

Memahami Metode Nearest Neighbour dalam Dunia Data Science
Dalam dunia data science dan machine learning, terdapat berbagai metode yang digunakan untuk melakukan klasifikasi, prediksi, atau pencarian pola dari sekumpulan data. Salah satu metode yang cukup sederhana namun sangat powerful adalah metode Nearest Neighbour. Metode ini sering menjadi pilihan dalam berbagai aplikasi, mulai dari sistem rekomendasi hingga pengenalan pola wajah. Mari kita bahas lebih dalam tentang apa itu metode Nearest Neighbour dan bagaimana cara kerjanya.
Apa Itu Metode Nearest Neighbour?
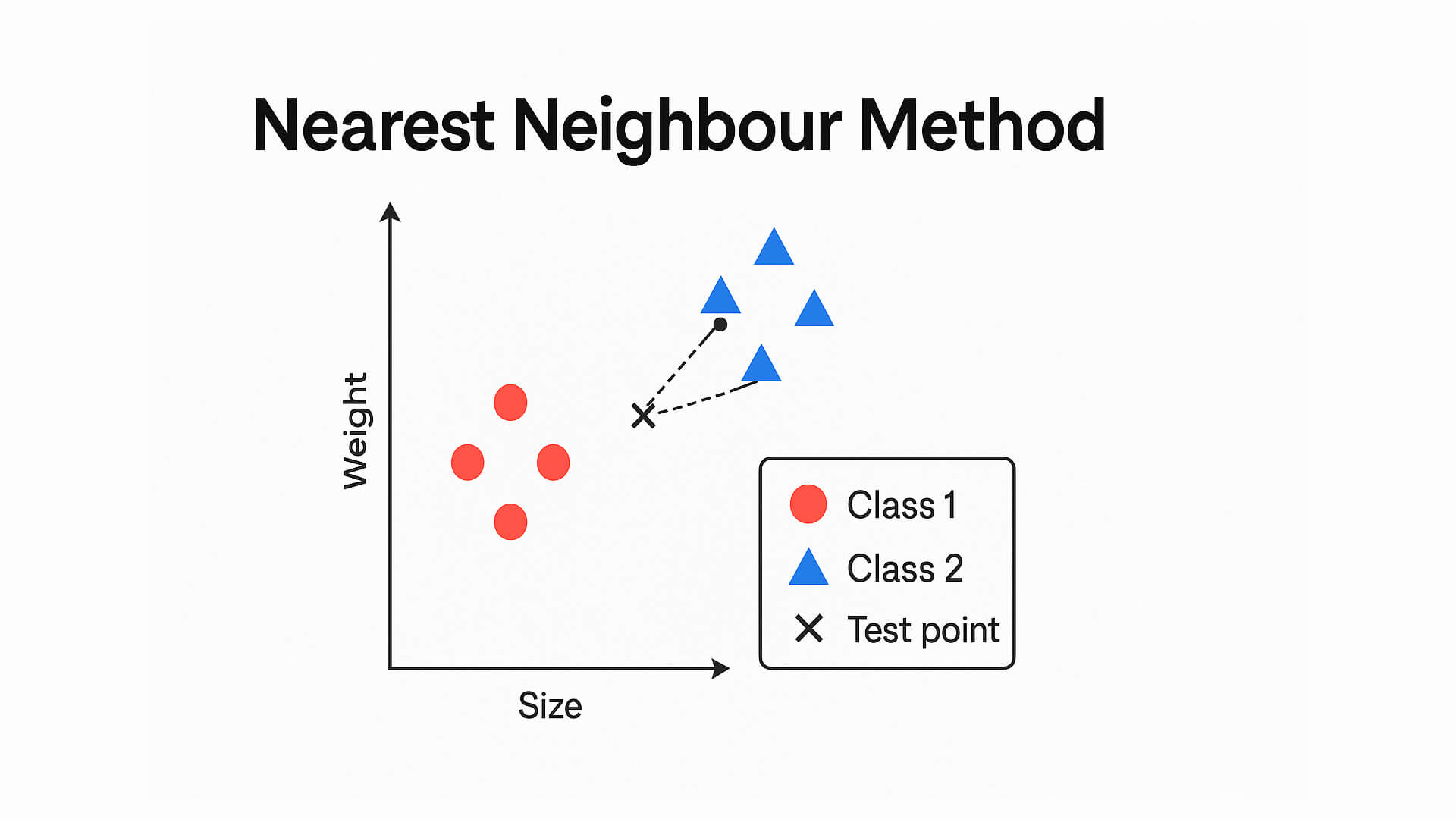
Metode Nearest Neighbour adalah algoritma yang digunakan untuk mengklasifikasikan data berdasarkan kedekatan atau kemiripan dengan data lain. Konsep dasarnya sangat sederhana: suatu data baru akan diklasifikasikan berdasarkan data yang paling dekat dengannya dalam ruang fitur.
Jika kita hanya menggunakan satu tetangga terdekat, maka metode ini disebut 1-Nearest Neighbour (1-NN). Namun, dalam praktiknya, kita sering menggunakan beberapa tetangga terdekat dan mengambil suara mayoritas dari mereka untuk menentukan hasil klasifikasi. Inilah yang dikenal sebagai k-Nearest Neighbour (k-NN).
Cara Kerja Nearest Neighbour
Secara umum, berikut adalah langkah-langkah kerja algoritma Nearest Neighbour:
-
Tentukan nilai k (jumlah tetangga terdekat yang ingin dipertimbangkan).
-
Hitung jarak antara data baru dan semua data yang sudah ada (bisa menggunakan jarak Euclidean, Manhattan, atau lainnya).
-
Pilih k data terdekat berdasarkan jarak tersebut.
-
Tentukan kelas dari data baru berdasarkan mayoritas kelas dari k tetangga terdekat.
Contoh Sederhana
Misalnya kita memiliki dataset buah-buahan berdasarkan berat dan ukuran. Jika ada buah baru dengan berat dan ukuran tertentu, maka kita bisa menggunakan metode Nearest Neighbour untuk menentukan apakah buah tersebut adalah apel, jeruk, atau pisang dengan membandingkannya dengan buah-buah yang sudah dikenal.
Kelebihan Metode Nearest Neighbour
-
Mudah dipahami dan diimplementasikan.
-
Tidak memerlukan asumsi distribusi data.
-
Efektif untuk dataset kecil hingga menengah.
Kekurangan Metode Nearest Neighbour
-
Memerlukan banyak memori, karena semua data latih harus disimpan.
-
Waktu prediksi lambat untuk data besar, karena harus menghitung jarak ke semua data.
-
Sensitif terhadap skala fitur, sehingga data perlu dinormalisasi.
Aplikasi Nyata
-
Sistem rekomendasi film atau produk.
-
Pengenalan wajah dan pengenalan tulisan tangan.
-
Deteksi penipuan berdasarkan perilaku transaksi.
-
Sistem diagnosis medis berdasarkan gejala pasien sebelumnya.
Penutup
Metode Nearest Neighbour membuktikan bahwa pendekatan yang sederhana bisa sangat efektif dalam dunia nyata. Dengan pemahaman yang baik tentang cara kerjanya dan kapan harus menggunakannya, metode ini bisa menjadi alat yang sangat berguna dalam analisis data.
Jika Anda baru memulai belajar machine learning, k-NN adalah salah satu algoritma terbaik untuk dipahami terlebih dahulu sebelum beralih ke metode yang lebih kompleks.

